
Fraud scoring usually breaks in one of two ways. The model misses harmful activity, or it catches too much legitimate activity.
The second failure creates review queues, delayed payouts, failed checkouts, appeals, and customer friction. It also teaches operators to distrust automated recommendations.
Decision-first fraud scoring treats this as an operating system problem, not only a classification problem. The system must connect predictions to policies, actions, evidence, ownership, and feedback.
Research on classifier calibration supports separating fraud predictions from the business logic that selects an action. That separation allows policy owners to change operating decisions without rebuilding the underlying classifier (arXiv, 2024).
The objective is not immediate autonomy. It is a controlled path from evidence to a reviewable decision.
When this needs an AI build
A dedicated AI build is appropriate when rules alone no longer express the patterns operators need to evaluate. It is also appropriate when risk evidence spans several systems and changes with context.
Strong buyer-fit signals include:
- Analysts repeatedly assemble the same evidence from payment, account, device, identity, and support systems.
- Static rules create large queues but still miss novel behavior.
- Different reviewers reach inconsistent outcomes from similar cases.
- Risk thresholds vary by product, region, payment method, or customer segment.
- Leaders cannot trace a decision to its data, model, policy, and reviewer.
- Appeals and overrides are recorded, but they do not improve later decisions.
- The business needs recommendations first and selective automation later.
An AI build is not justified by transaction volume alone. It should solve a defined decision problem with measurable operating consequences.
The payment fraud environment also changes as attackers adapt their methods. The European Banking Authority has documented emerging fraud types and possible mitigants, including measures beyond transaction authentication alone (EBA, 2024). That environment favors systems where policies and evidence sources can evolve independently.
Define the decision before the score
Start with a decision ledger. List every action the workflow can take today and every action it may take after modernization.
Typical actions include approve, request verification, hold, review, block, refund, release payout, suspend, and reopen after appeal. Each action needs an owner, evidence standard, latency target, and reversal path.
A checkout decision may require an immediate response. A seller payout review may allow more time when the evidence bundle is complete.
The ledger should also state the cost of each error. A false approval, unnecessary hold, rejected customer, and delayed payout do not create the same harm.
The joint ECB and EBA payment fraud report examines fraud across different payment instruments and transaction contexts (ECB and EBA, 2024). An implementation should preserve that context rather than compressing every case into one universal policy.
Implementation workflow and build path
decision-first fraud scoring decision matrix
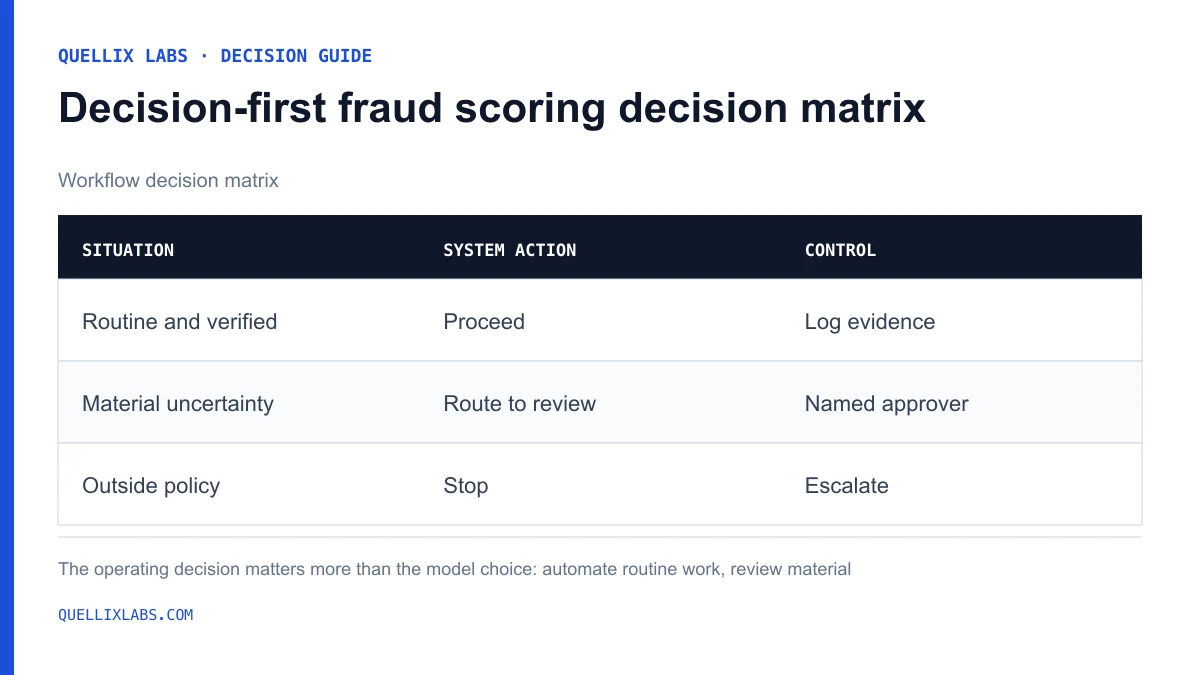
Read the data in this graphic
| Situation | System action | Control |
|---|---|---|
| Routine and verified | Proceed | Log evidence |
| Material uncertainty | Route to review | Named approver |
| Outside policy | Stop | Escalate |
The build path should separate observations, predictions, policies, and actions. Combining them in one rule table makes change difficult to audit.
1. Map decisions and outcomes
Document the current workflow from event arrival through final resolution. Include appeals, chargebacks, dispute outcomes, account recovery, and analyst overrides.
Define the observable outcome for each use case. Some outcomes arrive quickly, while others remain uncertain for weeks or months.
2. Create the evidence contract
Define the signals available at decision time. Examples include account age, payment velocity, device consistency, identity evidence, prior disputes, relationship changes, and document confidence.
For each signal, record its source, timestamp, owner, expected freshness, and missing-data behavior. Missing evidence should remain explicitly missing rather than becoming a silent zero.
3. Build a versioned feature layer
Normalize identifiers and event timestamps before model work begins. Keep online and offline feature definitions aligned where possible.
Store enough lineage to reproduce a historical score. Without reproducibility, analysts cannot distinguish a model defect from a data defect.
4. Train and calibrate the scoring layer
The model should estimate risk from the evidence available at that moment. Its output should not directly encode the final business action.
Calibration matters because a score must support policy decisions across segments and operating conditions. The classifier-calibration approach described in fraud research explicitly separates predictive scoring from business action logic (arXiv, 2024).
The Bank for International Settlements has also published a machine-learning framework for anomaly detection in payment systems (BIS, 2024). Anomaly detection can add useful evidence, but an unusual event is not automatically fraudulent.
5. Implement the policy engine
The policy layer maps score, confidence, evidence completeness, segment, and current controls into an allowed action. Policy changes should be versioned separately from model releases.
This separation lets risk leaders tighten a specific payout policy without changing checkout behavior. It also supports controlled rollback.
6. Design analyst queues
Each case should arrive with a compact evidence bundle. Show the recommendation, material signals, missing inputs, policy invoked, and source records.
Reviewers should be able to accept, override, request evidence, or flag a policy gap. Those outcomes need structured reason codes alongside optional notes.
Research on learning to defer examines routing decisions among multiple experts while accounting for error costs and workload constraints (TMLR, 2024). In practice, queue capacity should be part of system design rather than an afterthought.
7. Shadow, calibrate, and release
Run the new system beside the existing workflow before granting action authority. Compare recommendations with actual decisions and later outcomes.
Release one bounded use case first. Expand only after evidence quality, queue capacity, reversal handling, and monitoring are stable.
Decision architecture
The following table is a crawlable reference architecture. It separates components that teams often collapse into one service.
- Event intake: Primary responsibility: Receive and validate source events; Required record: Event ID, source, event time, schema version; Failure response: Quarantine or mark incomplete.
- Evidence layer: Primary responsibility: Resolve signals available at decision time; Required record: Feature values, freshness, missing fields; Failure response: Continue under explicit missing-data policy.
- Scoring layer: Primary responsibility: Estimate risk and confidence; Required record: Model version, score, calibration version; Failure response: Fall back to rules or review.
- Policy layer: Primary responsibility: Select an allowed action; Required record: Policy version, segment, rationale; Failure response: Use conservative routing policy.
- Review layer: Primary responsibility: Present evidence and capture judgment; Required record: Reviewer, action, reason, timestamp; Failure response: Escalate or request more evidence.
- Outcome layer: Primary responsibility: Attach confirmed or provisional results; Required record: Outcome type, source, maturity status; Failure response: Keep case open or label uncertain.
- Monitoring layer: Primary responsibility: Detect operational and segment drift; Required record: Metric window, alert, owner; Failure response: Pause automation or adjust policy.
Every production decision should become an immutable event. Store the input snapshot, model version, policy version, score, confidence, action, reviewer, reason, and known outcome.
That event history supports case reconstruction and portfolio analysis. It also shows whether an improvement came from data, scoring, policy, or reviewer behavior.
Illustrative routing thresholds
Thresholds should be selected through historical evaluation, shadow testing, and capacity planning. They should never be copied from a generic example.
The following values are hypothetical. They demonstrate routing structure only and are not recommended production defaults.
- 0.00-0.19: Illustrative route: Approve; Additional condition: Required evidence present; Intended control: Log and sample for review.
- 0.20-0.59: Illustrative route: Step-up or analyst review; Additional condition: Queue capacity available; Intended control: Collect more evidence.
- 0.60-0.84: Illustrative route: Priority review or temporary hold; Additional condition: Policy permits reversible hold; Intended control: Require reasoned human action.
- 0.85-1.00: Illustrative route: Escalate; Additional condition: Strong evidence and authorized policy; Intended control: Block only where approved.
A real implementation may use different bands by segment. A score can also route differently when confidence is low or evidence is stale.
No threshold should silently become an irreversible veto. High-impact actions need an explicit policy, accountable owner, and appeal path.
Operating model and measurement
Fraud analysts should not receive a raw score and a collection of browser tabs. They need a concise explanation, source evidence, and a clear next action.
Human approval is not a design weakness. It is a control surface during calibration and for cases where consequences remain high.
Measure the decision system, not only the model. Useful measures include:
- Fraud loss by decision cohort and outcome maturity.
- False positive rate by customer, product, region, and payment segment.
- Manual review rate and queue age.
- Approval, hold, and appeal resolution latency.
- Appeal reversal rate.
- Reviewer agreement and override frequency.
- Decisions made with missing or stale evidence.
- Automation coverage by action type.
- Customer friction indicators linked to the affected workflow.
Model precision can improve while operations become worse. For example, a stricter policy may shift costs into appeals or support contacts.
Evaluation should use time-based validation and segment analysis. Random splits can hide changing behavior and leakage from later outcomes.
Risks, limits, and when not to build
Do not build a decision-first fraud layer when core events cannot be reconciled. Broken identifiers, missing outcomes, and inconsistent timestamps will undermine evaluation and auditability.
Do not automate irreversible actions in the first release. Account closures, seller suspensions, payout holds, and blocks can carry contractual, regulatory, and trust consequences.
Segment harm is another material risk. Aggregate performance can conceal poor outcomes for a region, payment method, customer cohort, or merchant type.
The NIST AI Risk Management Framework organizes AI risk work around governance, mapping, measurement, and management (NIST, 2023). For fraud operations, that means named owners, documented policies, segment monitoring, and escalation routes.
Labels also have limits. A chargeback is not always proof of fraud, and the absence of a dispute is not always proof of legitimacy.
Reviewer feedback can introduce its own bias. Overrides should therefore be analyzed, not accepted automatically as perfect training labels.
Attackers may adapt after controls change. Monitor input distributions, action rates, queue composition, and delayed outcomes together.
Finally, avoid freshness theater. Frequent retraining adds little when policies are stale, feedback is missing, or no one can explain a hold.
What a good first release looks like
A strong first release covers one bounded decision. Examples include suspicious renewal routing, marketplace payout review, or step-up verification for one transaction flow.
It connects only the systems needed for that decision. It records complete decision events and gives reviewers structured override choices.
Leaders should be able to inspect one case and understand what happened. They should also be able to review a period of decisions by model, policy, segment, route, and outcome.
The release should have explicit rollback criteria. Examples include unavailable evidence, queue overload, unexplained segment changes, or rising appeal reversals.
These conditions are organization-specific. Teams must set them before launch rather than inventing them during an incident.
Review cadence after launch
Treat the first month as calibration rather than proof of success. Review samples from every route, including approvals, step-ups, holds, blocks, overrides, complaints, and appeals.
A useful weekly review produces three separate outputs:
- Update the policy table when a business rule is wrong or ambiguous.
- Update the evidence map when analysts repeatedly need missing context.
- Update evaluation cases when the model repeats a recognizable error.
Version these changes independently. Otherwise, teams cannot tell which intervention improved the workflow.
Maintain an exception register for repeated override patterns. Each exception should have a name, owner, severity, evidence requirement, and next action.
The long-term cadence can slow after the workflow stabilizes. High-impact decisions and emerging segments should still receive periodic review.
What Quellix would build
Quellix would begin with a technical decision review covering the ledger, data lineage, outcome maturity, policy ownership, and queue capacity. The output would define the narrowest production release worth implementing.
The build would usually include an event and feature pipeline, calibrated risk service, versioned policy engine, analyst queue, decision log, and monitoring layer. Existing rules would remain available as constraints or fallbacks.
The implementation would use recommendation mode before selective automation. Evaluation gates would cover performance, segment behavior, evidence completeness, latency, reversibility, and operational capacity.
This work fits Quellix Labs' Predictive Analytics and Recommendation Systems service context. The engagement focuses on governed decisions and production integration, not an isolated model demonstration.
The buyer next step is a technical review of one fraud workflow. Bring the current decision rules, sample cases, available outcomes, queue measures, and known exception patterns.
Related Reading
- Classifier calibration and business action separation for fraud prevention.
- Cost-sensitive deferral under expert workload constraints.
- AI risk governance across design, deployment, monitoring, and management.


