AI Agent Governance: Implementing Claude Fable 5
For years, enterprise AI has been confined to a digital box. You could ask a question, and it would provide an answer. But the release of Claude Fable 5 on June 9, 2026, has fundamentally changed the landscape [1]. We have moved from the era of static chatbots into the era of autonomous actors.
Claude Fable 5 is the first of the "Mythos-class" models [1]. It does not just process text. It possesses a unique ability to navigate complex, dynamic environments. Anthropic demonstrated this through visual gameplay in titles like Pokémon and Slay the Spire [1]. While gaming might seem like a distraction, for a business leader, it represents something far more valuable. It proves the ability to manage long-term strategy, resource allocation, and spatial reasoning within a digital interface.
However, with this new power comes a significant governance challenge. If an agent can navigate a complex game, it can navigate your CRM, your codebase, or your cloud infrastructure. Without a rigorous framework, you risk "ghost actions." These are changes made to your systems that no human requested and no one can explain. At Quellix Labs, we solve this through our operating loop framework and strict governance standards.
Fable 5 AI agent governance, explained
Fable 5-style AI agent governance means setting boundaries before an autonomous agent can affect real workflows. The important controls are approval gates, tool permissions, evaluation checks, fallback paths, and logs that show why the agent acted.
For teams evaluating high-autonomy agents, the question is not whether the agent can complete a task once. The question is whether it can operate repeatedly without hiding mistakes, escalating risky actions, or drifting from approved business logic.
When this needs an AI build
Not every business process requires a complex autonomous agent. However, manual workflows that bottleneck your operations demand a custom AI build. An autonomous agent build becomes worth evaluating when measured recurring work on multi-step, visual, or system-interactive tasks is material enough to justify the operating cost and risk. These tasks include triaging security alerts, updating CRM records across multiple legacy tabs, or resolving repetitive code bugs.
If your workflows require navigating dynamic user interfaces or making strategic trade-offs based on visual data, off-the-shelf software fails. A custom agentic system built on Claude Fable 5 bridges this gap. It automates complex, multi-step operations while maintaining strict enterprise compliance.
The Shift to Autonomous Operations
The primary business pain today is no longer a lack of data. It is the manual burden of acting on that data. Founders and operators are drowning in middle-office tasks. These tasks are too complex for simple automation but too routine for a high-paid engineer's time.
Claude Fable 5 changes the math [1]. Its ability to reason through multi-step problems allows it to take over these workflows. We call this the operating loop. But the cost of a mistake in a production environment is high. This is why governance must be built into the architecture. It cannot be added as an afterthought.
Governance model for safe agent actions
To deploy Claude Fable 5 safely, we utilize the Quellix governance model. This ensures that every action taken by an AI agent is intentional and auditable.
[Reason Phase: Analyze UI & State]
│
▼
[Act Phase: Execute in Sandbox]
│
▼
[Verify Phase: Run Safety Filters] ──(Exceeds Risk Threshold?)──► [Trigger HITL Approval Gate]
│ │
│ (Passes Filters) │ (Approved)
▼ ▼
[Commit Action to Production] ◄────────────────────────────────────────────┘1. Reason
The agent analyzes the input and the current state of the system. Using Fable 5's visual reasoning, it can "see" the UI or the architecture diagram [1]. This allows it to understand context that text-only models miss. It formulates a plan based on the available tools and permissions.
2. Act
The agent executes a specific, sandboxed action. This might be drafting a code patch or updating a lead status. Crucially, this action happens in an isolated environment. It does not touch the live production database yet.
3. Verify
This is the critical governance step. The system checks the action against pre-defined safety reauth filters [2]. If the action exceeds a certain risk threshold, it triggers a human-in-the-loop (HITL) approval. The agent must justify its decision before the action is committed.
By following this loop, we ensure that the agent does not hallucinate a solution. It validates its work before it ever touches your production data [3].
Workflow Implementation: The Build-Path for Code Remediation
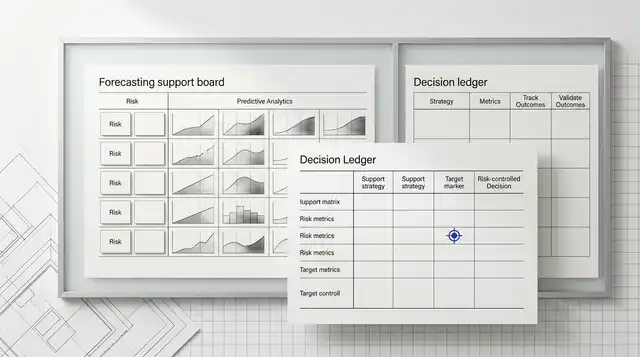
AI Agent Governance decision matrix

Read the data in this graphic
| Situation | System action | Control |
|---|---|---|
| Routine and verified | Proceed | Log evidence |
| Material uncertainty | Route to review | Named approver |
| Outside policy | Stop | Escalate |
Let's look at a concrete example of how Quellix Labs builds an autonomous workflow. Consider a software company struggling with a backlog of low-priority security vulnerabilities. This is a classic use case for Claude Fable 5.
Phase 1: The Input Layer
The system receives an automated alert from a security scanner. This could be Snyk or GitHub Advanced Security. The alert includes the vulnerable code snippet and the suggested fix. The agent ingests this data and begins its reasoning phase.
Phase 2: Contextual Navigation
Instead of just looking at the snippet, the agent navigates the repository. It uses its visual reasoning to understand how the vulnerable function is used across the application [1]. It maps out dependencies and potential side effects. This mimics the behavior of a senior security engineer.
Phase 3: Visual Verification and Testing
The agent spins up a local instance of the app. It uses visual reasoning to confirm that the vulnerability is reachable via the UI [1]. It then writes a patch and creates a new branch. It runs the existing test suite to ensure no regressions were introduced. If a test fails, the agent enters a self-correction loop.
Phase 4: The Safety Reauth Filter
This is where Claude Fable 5's new safety features come into play [1]. The agent cannot merge the code itself. Instead, it generates a summary of the change. It sends a notification to a senior developer. The developer must provide a biometric or MFA-backed reauth to authorize the merge. This lets the agent prepare the bounded work while a human remains the final authority for the merge.
Agentic Observability: Beyond Simple Logs
You cannot govern what you cannot see. Traditional logging tells you what happened. It does not tell you why an AI made a specific decision. For Claude Fable 5, we implement step-level logging using OpenTelemetry.
Every step of the operating loop is recorded. We capture the model's internal thought process and the visual state it was observing. We also log the specific safety filters that were triggered [2]. If an agent fails, we do not just see an error message. We see the exact moment its reasoning diverged from the expected path. This level of observability is non-negotiable for enterprise-grade AI [3].
Risks and Limitations of Autonomous Agency
While Claude Fable 5 is a massive leap forward, it is not a silver bullet [1]. Buyers must be aware of the trade-offs involved in building autonomous systems. Governance requires a clear understanding of these limitations.
1. The Cost of Reasoning
Claude Fable 5 is a Mythos-class model [1]. This means it is computationally expensive. Running an agent in an infinite loop can lead to unexpected cloud costs. At Quellix, we implement token budgets. We also use loop-limiters to prevent agents from spinning their wheels on unsolvable problems.
2. Latency vs. Safety
The more safety filters you add, the slower the agent becomes [2]. A support agent that checks five compliance databases will have higher latency. You must decide where the balance lies for your specific use case. In high-stakes environments like finance, we always prioritize safety over speed.
3. The Visual Logic Trap
Fable 5's ability to play games is impressive [1]. However, enterprise UIs are often messier than game interfaces. If your internal tools have inconsistent layouts, the agent's visual reasoning may fail. We often recommend a UI cleanup before full deployment. This provides the agent with a stable environment to work in.
4. Recursive Loop Inflation
Autonomous agents can sometimes enter a state of recursive reasoning. They may spend excessive tokens "thinking" about a task without taking action. We mitigate this by setting maximum reasoning steps. If the agent cannot reach a conclusion in ten steps, it must escalate to a human.
A Decision Framework for Model Selection
When should you use Claude Fable 5 versus a smaller model? We use the following decision rules to guide our clients:
- Use Claude Fable 5 if: The workflow requires navigating a complex UI [1]. It is ideal for making strategic trade-offs or handling unstructured visual data. If the task looks like a strategy game, Fable 5 is the right choice.
- Use a smaller model if: The task is a straightforward extraction-to-review pipeline. For example, pulling data from an invoice is better suited for Claude 3.5 Sonnet. Fable 5 is overkill and unnecessarily expensive for these tasks.
- Wait to automate if: The workflow requires high-level emotional intelligence. It is also not ready for physical-world interactions that digital agents cannot replicate. If the cost of a single error is catastrophic and cannot be caught by a filter, keep the process manual [3].
What Quellix would build
When partnering with enterprise teams, Quellix Labs designs and deploys custom agentic architectures tailored to your operational constraints. Through our AI Agent Development services, we build secure execution pipelines that integrate directly with your existing infrastructure.
Our custom builds feature sandboxed runtime environments, durable session layers, and multi-tenant safety reauth filters. We ensure that your Claude Fable 5 agents operate within strict, deterministic boundaries, giving your team full control over every autonomous action.
Implementation: Starting with a Technical Review
Building an autonomous agent is not just a coding project. It is an infrastructure project. It requires a durable session layer and a robust observability stack. Most companies fail because they try to build the agent first and the governance second.
At Quellix Labs, we start every engagement with a Technical Review. We look at your existing workflows and identify high-impact opportunities. We then design the safety filters required to keep your data secure [2]. Whether you are looking to automate your CRM or build a self-healing codebase, the path to success starts with architecture.
Claude Fable 5 has opened the door to a new level of efficiency [1]. But only those who build with rigor will realize the ROI. The question is no longer "Can AI do this?" The question is "How do we ensure AI does this safely?"