Permission-Aware AI Search for Secure Enterprise RAG
A useful enterprise assistant must know more than the answer. It must know whether the current user may retrieve the evidence behind that answer.
Permission-aware AI search enforces access policy before documents reach the language model. It returns citations from allowed sources and refuses requests when authorized evidence is unavailable.
That boundary matters whenever one knowledge environment serves users with different roles, groups, regions, customers, or clearance levels. Prompt instructions alone are not an access-control system.
When this needs an AI build
A dedicated build is justified when different employees should receive different results for the same query. Common examples include HR, finance, legal, sales, support, research, and customer account data.
A basic RAG prototype may be sufficient for public or uniformly shared material. Permissions-aware RAG becomes necessary when retrieval must reflect source-specific access rules.
The strongest buyer-fit signals are:
- Multiple repositories with different identity and permission models
- Group membership or document access that changes frequently
- Material consequences if restricted content appears in an answer
- A requirement to explain which evidence supported each response
- Administrators who need to investigate missing or excluded results
- Workflows that combine search with governed agent actions
The problem is not only model selection. It is an identity, policy, retrieval, evidence, and operations problem.
Permission-aware AI search, explained
Permission-aware AI search resolves the user's identity and entitlements before retrieval. The search layer applies those entitlements as filters or policy checks.
Microsoft describes security trimming as filtering search results according to user identity or group membership. Its Azure AI Search guidance places the filtering mechanism in the query path, rather than relying on the model to hide content afterward (Microsoft Learn).
Google Cloud documents a related source access-control pattern for Agent Search. The indexed access information is used to restrict results to documents the signed-in user can access (Google Cloud Documentation).
These product implementations differ, but the architectural principle is stable: unauthorized evidence should not enter model context.
This design also aligns with zero-trust reasoning. NIST states that zero trust does not grant implicit trust based only on network location or asset ownership (NIST SP 800-207). Each request should therefore be evaluated using current identity and policy information.
Reference architecture for permissions-aware RAG
The retrieval boundary should contain several independent controls. No single metadata field should carry the entire security model.
permission aware AI search control ledger
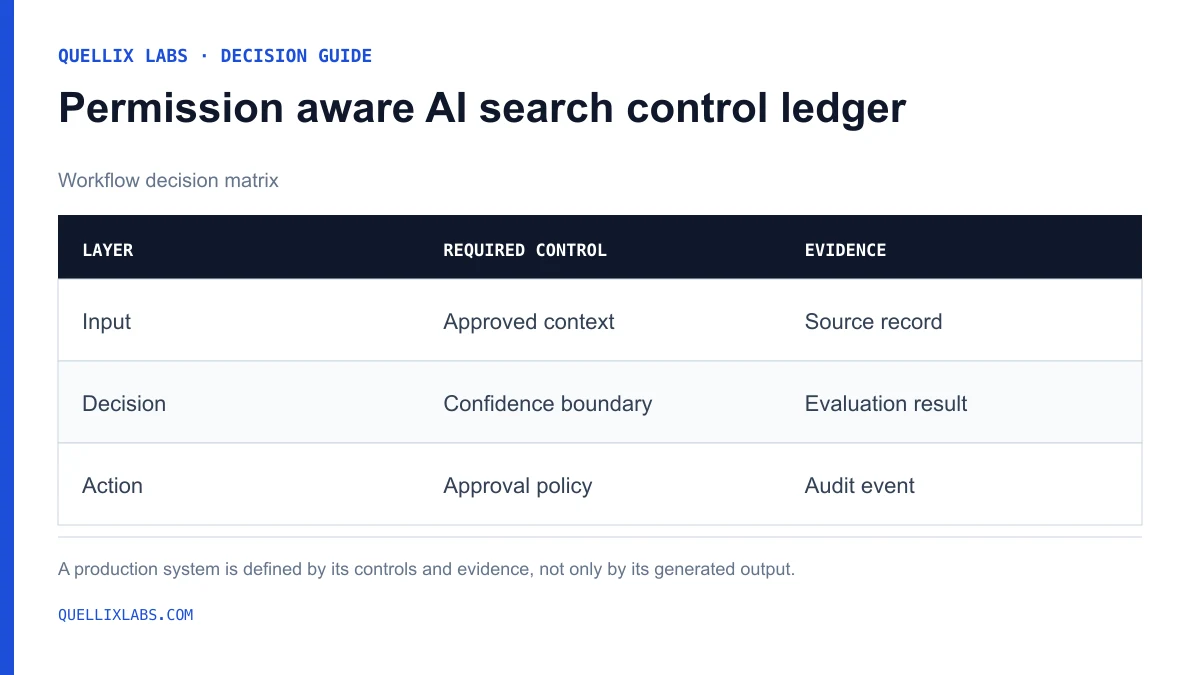
Read the data in this graphic
| Layer | Required control | Evidence |
|---|---|---|
| Input | Approved context | Source record |
| Decision | Confidence boundary | Evaluation result |
| Action | Approval policy | Audit event |
Crawlable architecture map: permission-aware request path
- 1. Authentication: Input: User session or workload identity; Required control: Validate issuer, audience, expiry, and tenant; Output: Trusted principal.
- 2. Entitlement resolution: Input: Principal, groups, roles, attributes; Required control: Resolve current access from authoritative systems; Output: Normalized entitlement set.
- 3. Policy translation: Input: Entitlements and query context; Required control: Convert source rules into retrieval constraints; Output: Search filter or policy decision.
- 4. Candidate retrieval: Input: Query and constraints; Required control: Search only within the permitted candidate set; Output: Allowed document candidates.
- 5. Reranking: Input: Allowed candidates; Required control: Prevent excluded documents from re-entering; Output: Ranked allowed evidence.
- 6. Generation: Input: Ranked evidence; Required control: Require source-grounded responses and citations; Output: Draft answer.
- 7. Validation: Input: Answer and cited evidence; Required control: Check citation presence, scope, and policy outcome; Output: Answer or refusal.
- 8. Audit logging: Input: Decisions and identifiers; Required control: Record policy version, filters, sources, and result; Output: Investigable trace.
This is the core of the Quellix "Cited Knowledge Loop." The phrase describes an implementation pattern, not a security standard.
The loop connects identity, retrieval, generation, citations, and audit evidence. Each answer should be traceable to content the user was allowed to retrieve at that moment.
1. Normalize identity and policy
Source systems rarely express access in exactly the same way. One repository may use groups, while another uses folders, domains, account teams, or record ownership.
A normalization layer should map those rules into a controlled policy model. The model might include tenant, user, group, department, region, document classification, and relationship attributes.
NIST defines attribute-based access control as authorization based on attributes associated with subjects, objects, requested operations, and relevant environment conditions (NIST SP 800-162). That model can inform a retrieval policy without requiring every source to adopt identical ACLs.
Normalization must preserve source semantics. It should not silently convert a deny rule into a broad allow rule.
2. Attach access metadata during ingestion
Each indexed document or chunk needs a stable connection to its source record and access policy. Useful fields can include source ID, tenant ID, allowed groups, denied principals, owner, classification, and policy version.
Chunk-level metadata must remain consistent with the parent document. Otherwise, one section may retain obsolete access after the source document changes.
The index is another governed copy of enterprise information. Encryption, deletion handling, backup controls, and administrative access still apply.
3. Filter before semantic retrieval
The preferred sequence is policy evaluation first, candidate retrieval second. The model should never receive excluded text.
A post-generation instruction such as "do not reveal payroll information" is not an equivalent control. The sensitive text has already crossed the retrieval boundary if it entered the prompt.
Pre-filtering may use native search filters, a policy decision service, physical index separation, or a combination. The right choice depends on tenant isolation, policy complexity, query volume, and source behavior.
4. Preserve policy through reranking and tools
Security filters must survive every retrieval stage. A reranker, cache, fallback search, or agent tool must not reintroduce excluded candidates.
Tool calls need the same principal and policy context as document retrieval. A search agent should not invoke a privileged connector under a shared administrator identity unless the workflow explicitly requires it.
5. Cite only allowed evidence
Citations help users inspect an answer, but citations do not prove authorization. The system must establish authorization before producing them.
Each citation should retain its source identifier, title, version, and retrieval decision. The destination link should also enforce source-system permissions when opened.
If the evidence is insufficient, the assistant should say so. It should not fill the gap from model memory or uncited restricted material.
Workflow and build path: a secure HR assistant
Consider an assistant that answers policy questions and supports compensation planning. Public holiday guidance and employee-specific payroll data require different controls.
Step 1: classify the request
A department head asks, "What remains in my team's bonus budget this quarter?" The application captures the authenticated principal, tenant, department, and relevant groups.
The request classifier identifies a compensation-planning workflow. Classification guides routing, but it does not grant access.
Step 2: resolve authorization
The policy service checks whether the user can view the requested department and planning period. It also distinguishes aggregate budget access from employee-level compensation access.
For an initial pilot, a five-minute permission propagation objective might be acceptable. That is an illustrative engineering target, not a universal standard.
Higher-risk deployments may require faster revocation. The acceptable window should come from the organization's threat model and operating procedures.
Step 3: choose the authoritative data path
Policy documents can be retrieved through RAG. A live remaining-budget figure should usually come from an authoritative finance or HR system through a governed tool call.
Embedding a changing balance may produce stale results. The agent can retrieve the relevant policy, call the approved budget endpoint, and cite both outputs appropriately.
Step 4: apply retrieval constraints
The policy decision might translate into constraints such as tenant, department, planning period, and permitted classification. These conditions are illustrative and must reflect the source system's actual rules.
The search service retrieves only allowed policy evidence. The structured tool receives the same scoped principal and department context.
Step 5: verify and answer
The system verifies that each cited source passed the current policy decision. It then generates a concise answer with the reporting period and source timestamp.
If the user asks for the chief executive's individual bonus, the policy service should deny the request. The assistant should return a bounded refusal without confirming whether a restricted record exists.
Step 6: record the decision
The trace records the principal identifier, policy version, applied constraints, connector, source IDs, tool outcome, and refusal reason code. Sensitive content should not be copied into logs by default.
An administrator can then distinguish an access denial from an indexing failure or an empty source result.
Build sequence and acceptance criteria
A production build should start with one bounded knowledge workflow. Indexing every repository first creates a large security and quality surface before policy behavior is understood.
Crawlable delivery map: phased implementation path
- 1. Policy discovery: Build activity: Map identities, groups, ACL inheritance, exceptions, and owners; Evidence required before proceeding: Approved source-to-policy matrix.
- 2. Connector prototype: Build activity: Ingest one source with stable IDs and deletion events; Evidence required before proceeding: Reconciliation report against source records.
- 3. Retrieval control: Build activity: Implement filters and policy decisions; Evidence required before proceeding: Positive and negative authorization tests.
- 4. Answer layer: Build activity: Add citations, refusal templates, and evidence checks; Evidence required before proceeding: Grounded-answer evaluation set.
- 5. Operations: Build activity: Add traces, alerts, replay tools, and runbooks; Evidence required before proceeding: Security and support review.
- 6. Expansion: Build activity: Add sources and agent actions incrementally; Evidence required before proceeding: Regression results for every policy class.
Acceptance criteria should include both allowed and denied queries. Teams should also test revoked users, nested groups, renamed documents, deleted records, cross-tenant requests, stale caches, and unavailable policy services.
A hypothetical pilot might target 100% blocking across a curated set of prohibited retrieval tests. It might also target a p95 response time below three seconds for standard document questions.
Those figures are example gates, not benchmarks. Production thresholds should reflect user needs, source latency, model latency, and security risk.
Agentic RAG observability
Agentic RAG observability should explain decisions without exposing restricted content. Logs need enough structure for investigation, but not a duplicate archive of prompts and documents.
Useful fields include:
- Pseudonymous principal or trace identifier
- Identity and policy provider versions
- Groups or attributes used in the decision
- Applied retrieval filter or policy decision ID
- Candidate and final source identifiers
- Citation validation outcome
- Tool names and scoped authorization context
- Refusal, timeout, and fallback reason codes
Administrative interfaces need their own access controls. A search system can enforce end-user permissions correctly while leaking content through an unrestricted trace viewer.
Monitoring should separate relevance failures from authorization failures. "No answer" may mean no matching document, an indexing delay, a policy denial, or an unavailable connector.
Risks and limits
Permission-aware retrieval reduces one major exposure path. It does not secure the full application by itself.
Stale permissions
A user may retain indexed access after removal from a source group. The design needs reconciliation, event handling, cache expiry, and a documented revocation objective.
For sensitive workflows, a failed entitlement lookup should normally fail closed. Availability requirements may justify another response, but that exception needs explicit approval.
ACL and group complexity
Nested groups, deny rules, shared links, external guests, and inherited folders can be difficult to reproduce. Simplifying these rules during ingestion may broaden access accidentally.
Physical separation may be safer for strict tenant boundaries. Metadata filters remain useful, but they should not be treated as the only isolation layer in every environment.
Index and cache leakage
Filtered retrieval does not protect unrestricted backups, caches, evaluation datasets, or administrator consoles. Every persisted copy needs ownership, retention rules, and access controls.
Side-channel disclosure
A refusal can still reveal that a document or employee record exists. Response templates should avoid confirming restricted entities unless policy permits that disclosure.
Weak source governance
AI search often exposes inconsistent ownership and outdated permissions. The build should pause if nobody can approve the source-to-policy mapping.
Exact operational data
RAG is not always the right path for balances, inventory, payroll figures, or other changing values. Governed API calls may be more reliable than retrieving embedded snapshots.
When not to build
A custom permission layer may be unnecessary for public documentation or a small repository shared uniformly by all users. A standard authenticated search endpoint can be simpler.
The project should also wait when identity systems are being replaced or access rules have no accountable owner. Automation will not resolve an undefined policy.
What Quellix would build
For an Enterprise AI Search and Knowledge Base engagement, Quellix would begin with identity and policy discovery. The build would then connect one high-value source and preserve its access semantics in retrieval.
The implementation path would include entitlement resolution, policy translation, filtered hybrid retrieval, citation validation, bounded refusals, and step-level traces. Governed agent tools would be added only where search alone cannot complete the workflow.
The first technical review would examine:
- Which source system should establish the initial permission model
- Which identity provider supplies users, groups, and attributes
- How quickly access changes must reach the search index
- Which queries require structured system calls instead of RAG
- Which denied-query tests represent unacceptable disclosure
- Which team owns policy exceptions and production incidents
The output should be a build decision, not a generic AI roadmap. Buyers should leave with a source map, policy model, pilot workflow, risk register, and measurable acceptance gates.
Related Reading
- Review the [reference architecture](#reference-architecture-for-permissions-aware-rag) for the complete request path.
- Use the [workflow and build path](#workflow-and-build-path-a-secure-hr-assistant) to scope an initial pilot.
- Apply the [risks and limits](#risks-and-limits) before approving production access.